Streaming Volumetric Images Online
Learnings and workflow from sending 3D color and depth images across networks in real time.

A few years ago I started working on an open source tool called Kinectron, affectionally taking its name from its two major components: Kinect + Electron. The software streams data from the Kinect V2 over the internet, making the data available client-side in the browser through an (easy to use ;) API.
One big challenge that I’ve run into is working with volumetric, or 3D, images across networks and in the browser. I’ve struggled to read them, store them, transfer them and unpack them. I’ve found workable, but far from perfect, solutions at each step. I’m writing my learnings and current workflow out in hopes of getting a better sense of where I’m at, where I should go next (especially with the discontinuation of the Kinect) and how other people are tackling the same issues.
Before I start, big thanks to Shawn Van Every, Wouter Verweirder, Aarón Montoya-Moraga and Or Fleisher for their contributions at different steps of the way.
Overview
The basic process that I’ve been working with is to capture color and depth images from a Microsoft Kinect, send them over a network using webRTC data channels, then unpack and render them in the browser. I’ll break the process into four steps: reading, storing, sending and drawing.
Step 1: Reading Depth Images
Thanks to the Kinect, most developers are now at least somewhat familiar with depth images and will have seen the sensor’s 8-bit, grayscale depth image. In this image, depth is represented in equal RGB values from 0–255. The darker the image (the smaller the number), the closer the object is, the lighter (the bigger the number) the farther the object is.

Although the 8-bit depth image is commonly used, the Kinect raw depth feed is 13-bit. The depth sensor has a range of eight meters, so 0–8000. (Note the reliability begins to degrade at about 4.5 meters, or 4500.) The data is stored in a 16-bit frame buffer, which from my tests is too large to send in real time on its own.
In order to make the raw depth data more manageable for sending online, I’ve been drawing the 13-bit image to an 8-bit image. Most images today have four channels: red, green, blue and alpha, or RGBA. Each of the channels can hold 8-bits. To use this typical configuration to hold a 13-bit image, the 13 bits are spread across two channels—R and G—and the B and A channels are left empty. Here’s what that looks like in code:
function processRawDepthBuffer(newPixelData) {
let j = 0;
for (let i = 0; i < imageDataSize; i+=4) {
imageDataArray[i] = newPixelData[j];
imageDataArray[i+1] = newPixelData[j+1];
imageDataArray[i+2] = 0;
imageDataArray[i+3] = 0xff; // set alpha channel at full opacity
j+=2;
}
}For comparison, here’s the code to draw the 8-bit grayscale depth:
function processDepthBuffer(newPixelData){
letj = 0;
for (let i = 0; i < imageDataSize; i+=4) {
imageDataArray[i] = newPixelData[j];
imageDataArray[i+1] = newPixelData[j];
imageDataArray[i+2] = newPixelData[j];
imageDataArray[i+3] = 0xff;
j++;
}
}When drawn to a canvas, the raw depth image looks like this.

Having the raw depth data stored in an RGBA image format rather than in a frame buffer makes it easier to work with across networks (more on that below…).
Step 2: Storing Color and Depth Images
Now that I have the depth image, it’s time to consider color. The Kinect provides a color image, but the Kinect’s color and depth cameras are different resolutions: 1920 x 1080 and 512 x 424 respectively. In order to use the different resolution images together, the color image must be registered to the depth image. Plenty of people have written about this (here’s one example), so I won’t go into detail here.
Assuming the color and depth images are now the same resolution, the question is how to store them to efficiently send and receive the images across networks. I’ve used two different approaches.
In the first approach, I capture and send the color and depth images separately. I include the 13-bit raw depth data in one image, and the color data in the other image.

In this case, there are two advantages: first, I can use a smaller lossy image format for the color image, which makes it easier to send, and second, I get the full depth resolution. However, lossy images are not optimized to compress depth data, so the depth image must be sent lossless to preserve the high depth resolution. Sending a lossless image across the network is space and bandwidth intensive, and sending it at the same time as the color image creates additional latency.
In the second approach, I combine the color and depth images on the server into one image. I use the RGB channels for the color data, and the A channel to hold the 8-bit grayscale depth data, creating an RGBD image. Then I send just the one image over the network.
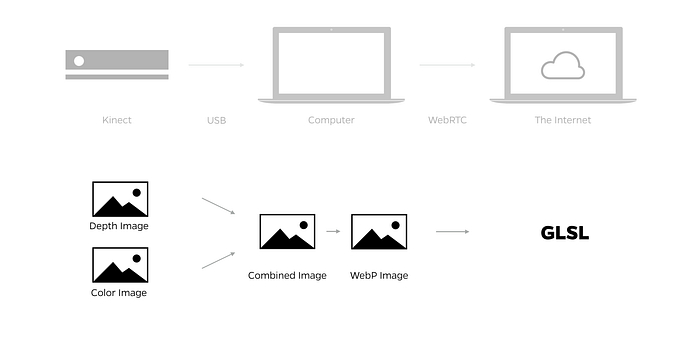
This is a good solution because it is an efficient use of space, but it sacrifices the full depth resolution. And again, the image needs to be lossless to retain the depth image, which makes the image too large to reliably send in real time over a network.
Interestingly, I can send the 512 x 424 four-channel raw depth image across a network and process the data into a point cloud at 24 fps or higher, but I cannot do the same at a reliable frame rate with the 512 x 424 RGBD image. I have assumed that even though the size of the image is the same, the complexity of the data (storing both color and depth in the same image) is requiring more bandwidth to send. This is a point for me to go back to and retest.
Image Format
When I receive the image buffers from the Kinect, I draw them onto HTML5 canvas elements, and convert them (using toDataUrl) to base-64 image data URLs that are ideal for sending across networks.
I tested several combinations of image formats to see what would work best to compress the images for sending over a network. WebP ended up being the best choice. JPG compression worked great for the RGB image, but it does not allow for an alpha channel. PNG and WebP allow for an alpha channel, and WebP was much smaller.
As I mentioned earlier, lossy image compression destroys depth data. Here’s a point cloud drawn in Three.js with Kinect color and raw depth data sent across my local network as WebP quality 1.0 (lossless):

Here’s the same scenario with raw depth data sent as WebP quality 0.99 (lossy).

This issue of storing volumetric data efficiently is a big sticking point for me and another place for me to continue researching alternative options. (Here are my rough notes from early 2016 for those interested in reading more about this process.)
Step 3: Sending Image Data Across Networks
Once I have the data URL of the color and depth images in WebP at my chosen quality, I send the image over WebRTC data channels using the open source library PeerJS. PeerJS uses UDP, rather than TCP. UDP allows the connection to drop packets without repercussions, which makes it ideal for streaming large amounts of data (learn more here). This is the most straightforward phase of my process (as of now!).
Step 4: Drawing Volumetric Images in the Browser
Once I have my volumetric data streaming, I use the Kinectron API to receive it in Three.js. I draw the data url to an image, then to a canvas, then I pull the pixels from the canvas with getImageData to manipulate them. (Chromium recently released new functionality to bypass this process with ImageBitmapRenderingContext. I will be looking into implementing this soon.)
In my first experiments I used the built-in Three.js point geometry to build point clouds with the incoming depth and color images. Here’s a gif of one of my first experiments using just raw depth data across my home Wi-Fi network (here’s an approximate version of this code).

In this next experiment I sent color and raw depth data as two images across my home network, and created a color point cloud in Three.js. I didn’t write down the fps at the time (and am having trouble finding the code…), but it has visible latency.
Despite the latency, I was content with the color point cloud as a reasonably good prototype of streaming realtime color volumetric video across a network and into my browser. From here, my research started moving toward working with color and depth feeds from two different sources. At this point I switched to writing custom shaders in Three.js to speed up the client-side processing. This is what it looked like (and here’s the code):
Whereas the previous examples were running with two separate images—raw depth and color images—for one person, the two person example is working from two RGBD images, one from each person. In order to send the data faster, I used lossy RGBD images, which caused a grid effect in the depth data (see gif below). The Kinect servers are streaming at 24 fps and placed in two different locations. (More about this project here.)
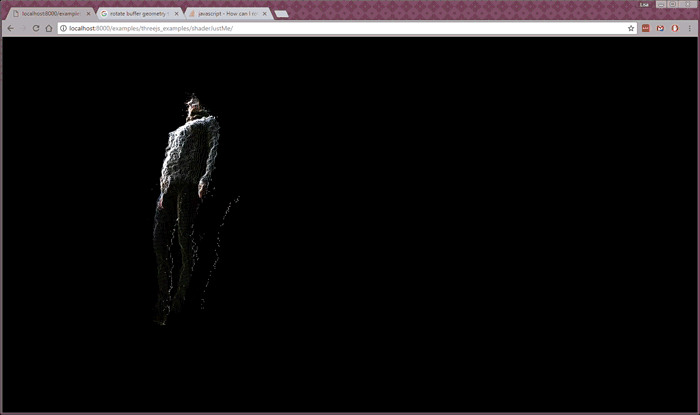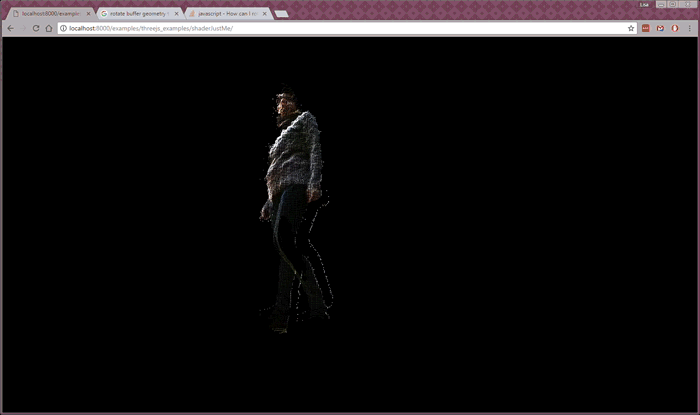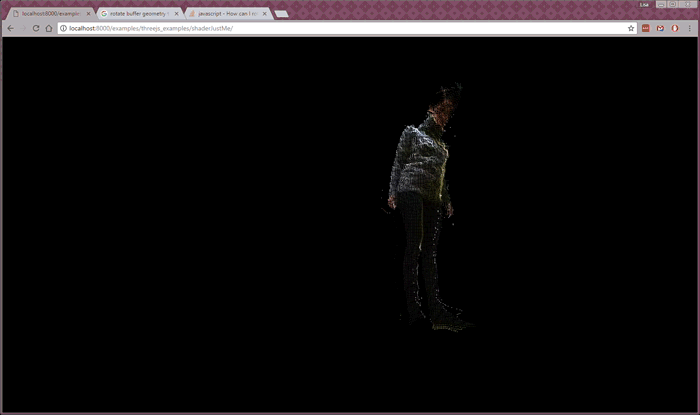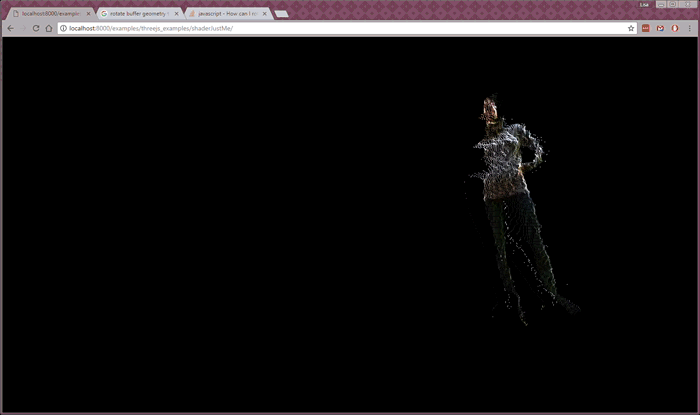
To me, this last experiment is closest to my ultimate goal—I’d like to build social, realtime volumetric experiences in the browser—but I have a way to go before this will feel like a workable, enjoyable experience for people.
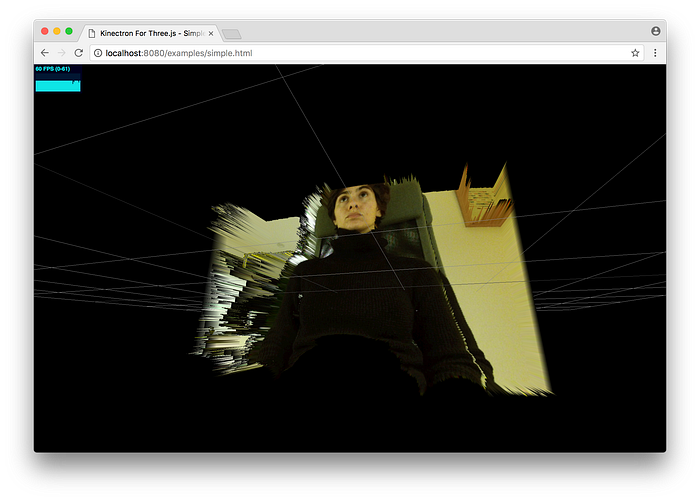
Three-Kinectron
Earlier this year Or Fleisher created Three-Kinectron, a plugin for working with RGBD data streamed from Kinectron in Three.js. It displays the RGBD feed as mesh, wire or points, and has methods that give the user easy access to properties like brightness, contrast and opacity.
Conclusions and Next Steps
It’s been exciting to revisit this workflow, and writing out the process has helped me see the places where I can dive back in. The most pressing of these points for now are: research more efficient ways to package depth data for streaming, implement ImageBitmapRenderingContext to speed up processing on both ends and test out the viability of replacing Kinect with the Intel RealSense sensor.
I’m also excited about a project that is currently underway between NYU Shanghai and NYC as part of the NYU Visual Arts Initiative Grant. We are working on the server side to send only the color and depth data associated with people in the scene, which would allow us to broadcast people without the background. I think this has the potential to cut down on bandwidth usage, and lead to a number of interesting applications.
I wrote this article to document work I’ve been doing on the open source software, Kinectron. Kinectron is a realtime peer server for Kinect V2 that makes skeletal and volumetric data available in the browser through a high-level API.
I developed Kinectron with Shawn Van Every under the Google Experiments in Storytelling (xStory) Grant at New York University’s Interactive Telecommunications Program (ITP). It is currently under development. Please get in touch if you’d like to contribute.
